
线上服务咨询
一句话+一张图——说清楚Aprioir关联规则算法
发表时间:2018-06-25 14:59:39
文章来源:未知
浏览次数:0次
一句话
关联分析(关联规则学习): 从大规模数据集中寻找物品间的隐含关系被称作 关联分析(associati analysis) 或者 关联规则学习(association rule learning)
一张图

解释一下这张图:
在关联规则Aprioir算法中,有两个很重要的概念,分别是频繁项集(frequent item sets),关联规则(associational rules),它们是用来描述隐含关系的形式。
频繁项集(frequent item sets): 经常出现在一块的物品的集合。
关联规则(associational rules): 暗示两种物品之间可能存在很强的关系。
那么 频繁 的定义是什么呢?怎么样才算频繁呢? 度量它们的方法有很多种,这里我们来简单的介绍下支持度和可信度。
支持度: 数据集中包含该项集的记录所占的比例。例如上图中,{豆奶} 的支持度为 4/5。{豆奶, 尿布} 的支持度为 3/5。
可信度: 针对一条诸如 {尿布} -> {葡萄酒} 这样具体的关联规则来定义的。这条规则的 可信度 被定义为 支持度({尿布, 葡萄酒})/支持度({尿布}),从图中可以看出 支持度({尿布, 葡萄酒}) = 3/5,支持度({尿布}) = 4/5,所以 {尿布} -> {葡萄酒} 的可信度 = 3/5 / 4/5 = 3/4 = 0.75。
举个栗子呗
还是上面的那个尿布和葡萄酒的栗子,让我们仔细的看一下它的关联规则的发现过程(Aprioir)
过程1:寻找k项频繁集
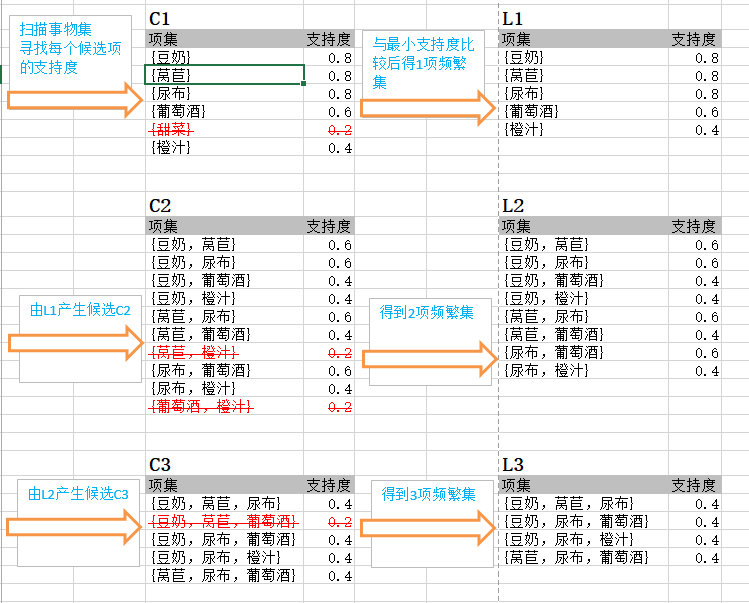
我们规定最小支持度为0.3
L1为1项频繁集,可以从图中看出它的计算过程为:
P(豆奶)=豆奶出现的次数 / 订单总数量P(豆奶)=豆奶出现的次数订单总数量
L2为2项频繁集,从L1中选择候选者(去除了小于最小支持度的数据),计算过程为:
P(豆奶,莴苣)=豆奶,莴苣共同出现的次数 / 订单总数量P(豆奶,莴苣)=豆奶,莴苣共同出现的次数订单总数量
同理可以推出L3
过程2:发现关联规则

这里举一个例子说明,买了尿布的人也会继续买葡萄酒的规则,支持度为0.6(前面已经算出),那么它的置信度计算过程为:
P(尿布−−>葡萄酒)=尿布,葡萄酒同时出现的概率 / 尿布出现的概率=P(葡萄酒|尿布)
希望能为您带来帮助,更多详情请继续关注我们洛阳软件开发!
